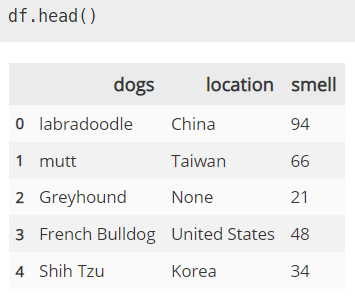
간혹 코딩을 하다보면 테스트를 하기 위해서 혹은 샘플이 필요해서 데이터프레임을 만들고 싶을 때가 있다. 그때마다 student_card = pd.DataFrame({'ID':[20190103, 20190222, 20190531], 'name':['Kim', 'Lee', 'Jeong'], 'class':['H', 'W', 'S']}) 이런식으로 만드려고한다면 여간 머리가 지끈지끈해지는게 아니다. 게다가 한번에 대용량의 데이터를 만들 수가 없다. 하지만 아래의 방법을 쓴다면 누구나 쉽게 내가 원하는 크기의 데이터프레임을 만들 수 있다. import pandas as pd import numpy as np size = 10_000 df = pd.DataFrame() df['position'] = np.rand..