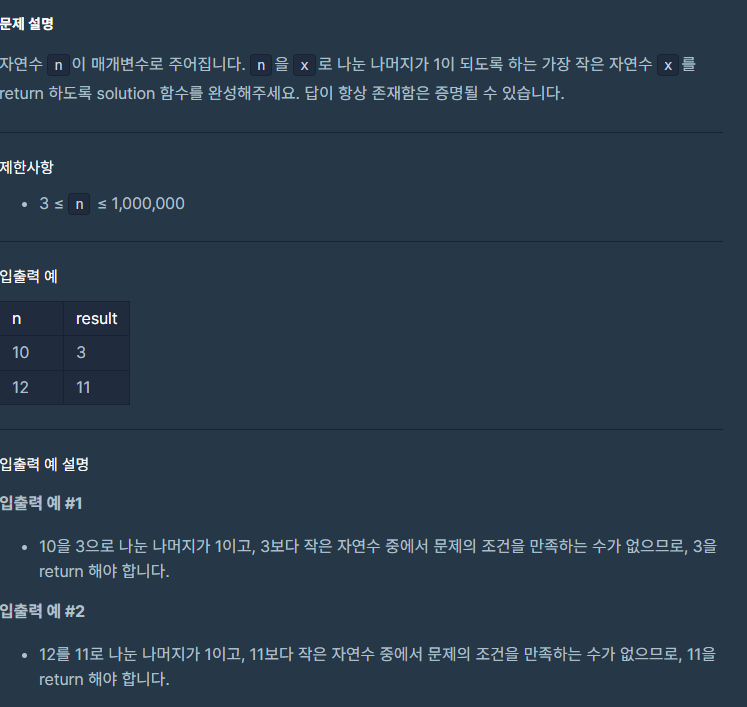
공모전이랑 다른 일들때매 바쁘다가 마무리되고 오랜만에 심심해서 코테 안푼 거나 풀어보았다. 코딩테스트 연습 - 나머지가 1이 되는 수 찾기 자연수 n이 매개변수로 주어집니다. n을 x로 나눈 나머지가 1이 되도록 하는 가장 작은 자연수 x를 return 하도록 solution 함수를 완성해주세요. 답이 항상 존재함은 증명될 수 있습니다. 제한사항 입 programmers.co.kr 예전의 나였으면 수학적인 걸 우선적으로 찾으려 했을텐데 오늘은 귀찮아서 다 돌리다가 나머지 1나오면 되지뭐..하고 코드를 짰다. def solution(n): for i in range(2,n): if n%i == 1: break return i 1부터 시작해버리는 건 의미없어서 2부터 시작~ 굉장히 쉽게 풀렸다.